Älyverkko CLI application
Table of Contents
- 1. Introduction
- 2. Concept glossary
- 3. Installation
- 4. Usage
- 5. Getting the source code
- 6. Feature ideas
1. Introduction
The Älyverkko CLI application is a user-friendly tool developed in Java, specifically tailored to streamline the utilization of expansive language models through CPU-based computation in batch processing mode.
To illustrate its capabilities: Imagine harnessing the power of a vast language model, boasting approximately 100 billion parameters, solely relying on CPU computations and leveraging the open-source software llama.cpp. This setup requires a modern consumer-grade CPU and approximately 128 GB of RAM. To put this into perspective, 128 GB of RAM is financially comparable to purchasing a high-quality smartphone, making it an economical option for many users.
In contrast, executing the same model on an Nvidia GPU could result in costs that are significantly higher, potentially at least by an order of magnitude.
However, there is a trade-off: CPU-based processing for such extensive models is inherently slow. This means real-time interaction, like chatting with the AI, wouldn't be practical or enjoyable due to the lag in response times. Nevertheless, when deployed in a non-interactive batch mode, this "slow but smart" AI can complete numerous valuable tasks within a 24-hour window. For instance, it could generate a substantial amount of code, potentially exceeding what you could thoroughly review in the same timeframe. Additionally, it could process more documents than most individuals would be inclined to read manually.
The primary objective of the Älyverkko CLI project is to identify and enable applications where this "slow but smart" AI can excel. By utilizing llama.cpp as its inference engine, the project aims to unlock a variety of uses where batch processing is more advantageous than real-time interaction.
Here are some practical examples of tasks suited for the Älyverkko CLI application:
In summary, the Älyverkko CLI application opens up a realm of possibilities for leveraging powerful AI in scenarios where immediate responses are not critical, but high-quality batch processing output is highly beneficial.
Note: project is still in early stage.
1.1. Use cases
1.1.1. Domain: Natural Language Processing (NLP)
Problem Statement:
Analyze a set of customer reviews to determine overall sentiment and extract key features that customers appreciate or dislike about a product.
Usage Procedure:
- User collects customer reviews in plain text format within the configured tasks directory. Lets say, about 150 kilobytes of reviews per input file (this is dictated by AI model available context size).
- Each review file starts with special "TOCOMPUTE:". (See: Task file format)
- The Älyverkko CLI application processes these files, generating sentiment analysis results and feature extraction insights.
- Results are appended to the original files in org-mode syntax, indicating AI responses.
1.1.2. Domain: Code Generation
Problem Statement:
Generate code snippets for a new software module based on detailed specifications provided by the developer.
Usage Procedure:
- Developer writes specifications in a text file within the tasks directory. Text file also contains relevant parts of the program source code and documentation. Älyverkko CLI "joinfiles" command can be used to facilitate such text file preparation.
- The Älyverkko CLI application processes this file and generates the corresponding code snippets. The generated code is appended to the original specifications file, organized using org-mode syntax.
- Developer can review proposed changes and then integrate them back into original program source code.
Note: Large part of the Älyverkko CLI program code is written in such a way by AI.
1.1.3. Domain: Content Creation
Problem Statement:
Draft an outline for a book on science fiction or improve its plot.
Usage Procedure:
- The book author writes a brief describing the outline of the plot and his book main idea for the novel.
- Älyverkko CLI processes this description and generates more detailed outline with suggested headings and suggests possible improvements to the plot.
Here is example sci-fi book that was written with the help of Älyverkko CLI.
1.2. Why Bother With This Setup? (The Big Picture)
Before diving into steps, let's address the elephant in the room: Why go through this setup when ChatGPT is just a click away?
Because Älyverkko CLI solves a fundamentally different problem:
- ✨ Privacy by design: All processing happens on your machine - no data ever leaves your computer
- 💰 Cost efficiency: Run 70B+ parameter models without paying per token (128GB RAM ≈ cost of a smartphone)
- ⚙️ Full control: Tweak every parameter to match your specific needs
- 📦 Offline capability: Works without internet connection
- 🕒 Batch processing: Perfect for "set it and forget it" workflows while you sleep
This isn't designed for real-time chatting (CPU inference is slow), but for substantial tasks where quality matters more than speed: code generation, document analysis, content creation, etc.
2. Concept glossary
2.1. General concepts
2.1.1. Task
A task represents a single unit of work submitted to the Älyverkko CLI system for AI processing.
Task logically consists of two core components:
- a system prompt (defining the AI's role/behavior) and
- a user prompt (the specific request or question).
Tasks are implemented as plain text files that begin with a
"TOCOMPUTE" header line specifying processing parameters. When
processed, the system appends the AI's response in structured format
and renames the file with a DONE: prefix. Tasks represent the
fundamental interaction pattern between users and the system - you
create a task file, Älyverkko CLI processes it while you work on other
things, and later you receive the completed response. The asynchronous
nature makes this ideal for CPU-based batch processing where responses
may take minutes to hours.
2.1.2. Skill
- See also:
A skill is a predefined behavioral configuration for the AI, implemented as a YAML file in the skills directory. Each skill defines:
- A system prompt that establishes the AI's role and behavior.
- System prompt will have special marker
<TASK-FILE>where specific user task will be injected.
- System prompt will have special marker
- Optional generation parameters (temperature, top-p , etc.)
- Optional Model alias that will be selected when this skill gets invoked.
Skills function as specialized "personas" for different task
types. For example, a summary.yaml skill might contain instructions
for concise text summarization, while a writer.yaml skill could
optimize for creative prose. The power of skills lies in their
reusability - once defined, you can apply the same behavioral
configuration across countless tasks by simply referencing the skill
name in your task TOCOMPUTE: header. Skills abstract away repetitive
instructions, letting you focus on the actual content of your request
rather than constantly redefining how the AI should behave.
2.1.3. Model
A model refers to a specific AI language model implementation in GGUF format, capable of processing tasks. Each model is configured with:
- An alias (e.g., "default", "mistral")
- File name of the GGUF model file
- Context size (maximum tokens processable)
- Optional generation parameters
- Optional end-of-text marker
Models represent the underlying neural network "brains" of the system.
While skills define how the AI should behave, models determine
what the AI is capable of. Larger models (e.g., 70B+ parameters)
generally produce higher quality outputs but require more RAM and
process slower. The system supports multiple registered models,
allowing you to select the appropriate capability/performance tradeoff
for each task via the model= parameter in your task file. Models are
typically stored in the models_directory and must be compatible with
llama.cpp for CPU-based inference.
2.1.4. "TOCOMPUTE" Marker
The TOCOMPUTE: marker is a special header line that must appear as
the first line of any task file to trigger processing.
Example:
TOCOMPUTE: skill=default model=default priority=5
This line specifies three critical parameters:
skill=: Which behavioral configuration to use (default: "default")model=: Which AI model to execute the task (default: "default")priority=: Integer determining processing order (higher = sooner)
The presence of this marker transforms an ordinary text file into an executable task. Älyverkko CLI ignores files without this header, allowing you to safely save draft versions. When you're ready for processing, simply add this line and save the file - the daemon will detect the change within seconds and queue the task. This marker-based system enables asynchronous workflow: prepare your task at your pace, then signal completion with this single line.
2.1.5. "DONE" Marker
The DONE: marker appears as the first line of processed task files,
replacing the original TOCOMPUTE: line. Its format documents exactly
how the task was processed:
DONE: skill=default model=default duration=2m
This line records:
- Which skill was used
- Which model processed the task
- How long processing took (in seconds/minutes/hours)
The DONE marker serves multiple critical functions: it prevents
reprocessing of completed tasks, provides an audit trail of processing
parameters, and gives immediate visual feedback about the task's
execution environment. Combined with the structured * USER: and *
ASSISTANT: sections that follow, it creates a self-documenting
conversation history that preserves both the original request and AI
response in context. This format enables iterative refinement - you
can review the AI's response, add follow-up questions, and re-add a
TOCOMPUTE: line to continue the conversation.
2.1.6. Priority
Priority is an integer value specified in the TOCOMPUTE: header
(e.g., priority=10) that determines task processing order. Higher
integer values indicate higher priority - a task with priority=10
will process before one with priority=5. The system uses a priority
queue that processes tasks in descending priority order, with random
tiebreakers for equal priorities.
This feature is essential for managing multiple concurrent tasks. For example:
- Urgent tasks:
priority=100 - Normal tasks:
priority=0(default) - Low priority background tasks:
priority-10=
When you have many tasks queued (e.g., overnight processing), priority ensures critical work gets attention first. The flexible integer system allows fine-grained control - you're not limited to just "high/medium/low" but can create nuanced priority tiers matching your workflow. Note that extremely high priorities won't make processing faster (that depends on model/hardware), but will ensure those tasks jump the queue.
2.1.7. System Prompt
The system prompt is the foundational instruction set that defines
the AI's role, behavior, and constraints for a task. It's implemented
through skills as the prompt field in YAML files, containing the
special <TASK-FILE> placeholder where user input gets injected.
Characteristics of effective system prompts:
- Establish clear role ("You are an expert Python developer…")
- Define output format requirements
- Set behavioral boundaries
- Include domain-specific knowledge
For example, a code review skill's system prompt might:
- Instruct the AI to analyze for security vulnerabilities
- Require responses in markdown with specific sections
- Specify ignoring certain file types
- Define severity classification standards
The system prompt operates "behind the scenes" - users never see it directly in task files, only its influence on the AI's responses. Well-crafted prompts dramatically improve output quality by providing consistent context across all tasks using that skill. They represent the primary mechanism for customizing AI behavior without retraining models.
2.1.8. User Prompt
The user prompt is the specific request, question, or content you
provide as input to the AI within a task file. It appears after the
TOCOMPUTE: header and forms the substantive content the AI will
process.
Effective user prompts typically:
- Clearly state the desired outcome
- Provide sufficient context
- Specify any constraints or requirements
- Reference relevant materials when needed
For example, a good user prompt for code generation might:
Generate a Python function that processes CSV files, handling: - Missing values by interpolation - Date formatting in ISO 8601 - Memory efficiency for large files Include docstrings and type hints. Target Python 3.10+.
Unlike the system prompt (which defines how the AI behaves), the user prompt defines what specific work should be done. It's where you bring your domain knowledge and task requirements to the interaction. Well-structured prompts yield significantly better results - the AI can only work with what you provide.
2.1.9. Model Library
The model library is the internal registry of all available AI models configured in the system. It's constructed during startup from:
- The
modelslist in the configuration file - Verified model files in the models directory
Key functions of the model library:
- Validates model file existence
- Resolves relative/absolute paths
- Provides model lookup by alias
- Manages default model selection
When you run alyverkko-cli listmodels, it queries this library to
show available models (marking missing files with "-missing"). The
library ensures that when a task specifies model=mistral, the system
can locate the correct GGUF file and its associated parameters. It
serves as the critical bridge between your configuration and the
actual model files on disk, handling all path resolution and
validation so your tasks can reference models by simple aliases.
2.1.10. GGUF Format
GGUF is the binary model format used by llama.cpp for AI inference.
Key advantages for Älyverkko CLI users:
- Enables CPU-only operation (no GPU required)
- Multiple quantization levels (Q4_K, Q8_0, etc.)
- Active development community
When downloading models, you'll typically see filenames like
model-Q4_K_M.gguf where the suffix indicates quantization
level. Lower quantization (Q4) uses less RAM but sacrifices some
quality; higher (Q8) preserves more accuracy at greater memory
cost. The format's efficiency is why you can run 70B+ parameter models
on consumer hardware - a 4-bit quantized 70B model requires "only"
~40GB RAM versus hundreds of GB for full precision.
2.1.11. llama.cpp
llama.cpp is the open-source inference engine that powers Älyverkko
CLI's CPU-based AI processing. It's a critical dependency, in
particular a standalone executable (llama-completion) that handles:
- Loading GGUF format models
- Tokenization and detokenization
- Core neural network computations
- Generation parameter application
Key features enabling Älyverkko CLI's functionality:
- Optimized CPU kernels for AVX2/AVX512
- Quantization support for memory efficiency
- Batched/unattended processing capabilities
- Cross-platform compatibility
Älyverkko CLI acts as a sophisticated wrapper around llama.cpp
llama-completion executable binary, managing the complex workflow of
task processing while leveraging llama.cpp's efficient inference
capabilities. The llama_cli_path configuration specifies where to
find this executable, which must be built separately from source to
optimize for your specific CPU. Without llama.cpp, Älyverkko CLI
couldn't execute any AI tasks - it's the actual "brain" behind the
system.
2.2. Important files and directories
2.2.1. Configuration File
The configuration file (default ~/.config/alyverkko-cli.yaml) is
the central YAML file defining all system parameters. It contains four
critical sections:
- Core Paths:
tasks_directory: Where task files livemodels_directory: Location of GGUF model filesskills_directory: Directory for skill YAML filesllama_cli_path: Path to the llama.cpp executable
- Generation Parameters:
- Global defaults for temperature, top_p, etc.
- Affects all tasks unless overridden
- Performance Tuning:
thread_countandbatch_thread_countoptimized for your specific hardware
- Model Definitions:
- Aliases, paths, and parameters for each registered model
This file serves as the system's blueprint - without it, Älyverkko CLI doesn't know where to find models, tasks, or how to process them. The configuration wizard simplifies initial setup, but advanced users often edit this file directly for fine-grained control. Parameter precedence follows skill > model > global rules, creating a flexible hierarchy for managing complex workflows.
2.2.2. Skill Directory
The skill directory (configured via skills_directory) is the
filesystem location where YAML files defining AI behaviors are stored.
Each file in this directory represents a distinct skill (e.g.,
default.yaml, summary.yaml), with the filename (minus extension)
serving as the skill's alias.
This directory enables:
- Organization of different AI personas
- Easy addition/removal of capabilities
- Version control of prompt engineering
- Sharing of skill configurations
When setting up Älyverkko CLI, you typically start with sample skills from the documentation, then gradually customize them to match your needs. The directory structure keeps your behavioral configurations separate from model files and task data, creating clean separation of concerns. Skills are reloadable at runtime - modifying a skill YAML file automatically affects subsequent tasks using that skill, without requiring Alyverkko CLI restart.
2.2.3. Task Directory
The task directory is the designated filesystem location where users
place task files for processing, configured via tasks_directory in
the YAML configuration file. Älyverkko CLI continuously monitors this
directory using filesystem watchers for new or modified files. When a
file with a TOCOMPUTE: header is detected, it's added to the
processing queue according to its priority. After completion, the
original file is renamed with a DONE: prefix. This directory serves
as the central hub for user-AI interaction - users create and edit
task files here using their preferred text editor, and completed
results appear in the same location.
You might wonder: Why deal with text files when everything has beautiful interfaces these days?
Because this is designed for productivity, not conversation:
- No waiting around: With CPU inference, responses take minutes/hours. File-based workflow lets you queue tasks and get back to work.
- Natural integration: Works with your existing text editor (VS Code, Emacs, etc.) rather than forcing a new interface.
- Version control friendly: You can track changes to prompts/responses with Git.
- Scriptable: Easily integrate with other tools in your workflow.
- Tasks directory can be synchronized with Dropbox/Syncthing or similar tools between multiple computers or users. This way, travel laptop can utilize processing capability or more powerful computer at home while being connected to internet at irregular intervals.
Think of it like email versus phone calls - sometimes asynchronous communication is actually more productive.
2.3. Generation parameters
2.3.1. Temperature
Temperature is a generation parameter controlling the randomness and creativity of AI responses, typically ranging from 0.0 (completely deterministic) to 2.0+ (highly creative). Lower values produce more focused, predictable outputs ideal for factual tasks, while higher values encourage diverse, unexpected responses better for brainstorming.
The parameter operates through a sophisticated probability distribution:
- Temperature = 0.0: Always selects highest-probability token (repetitive but reliable)
- Temperature = 0.7: Balanced exploration (common default)
- Temperature = 1.5+: Significant randomness (may produce nonsensical outputs)
Älyverkko CLI implements a three-tier hierarchy for temperature settings: skill-specific > model-specific > global default. This allows precise control
- your
creative-writing.yamlskill might use temperature=0.9 - while your
code-review.yamlskill uses 0.2.
The system automatically selects the most specific applicable value, giving you surgical control over response characteristics without modifying model files.
2.3.2. Top-p (Nucleus Sampling)
Top-p (or nucleus sampling) is a generation parameter (range 0.0-1.0) that dynamically selects the smallest set of highest-probability tokens whose cumulative probability exceeds the p-value. For example, with top_p=0.9, the model considers only tokens comprising the top 90% of the probability distribution.
- Low values (0.3-0.6): Focused, conservative responses
- Medium values (0.7-0.9): Balanced exploration (common default)
- High values (0.95+): Maximum diversity within coherence
Unlike temperature which affects all tokens uniformly, top-p dynamically adjusts the token selection pool based on the current context's probability distribution. This often produces more natural variation in responses. Like other parameters, top-p follows the skill > model > global hierarchy, allowing context-specific tuning. The default setting (typically 0.9-0.95) works well for most general-purpose tasks while preventing extremely low-probability ("nonsense") outputs.
2.3.3. Repeat Penalty
Repeat penalty is a parameter (>0.0) that discourages the AI from repeating identical phrases or tokens. A value of 1.0 means no penalty, while values >1.0 increasingly penalize repetitions. For example, repeat_penalty=1.2 applies a 20% reduction to the probability of tokens that have recently appeared.
This parameter is crucial for maintaining response quality in longer outputs:
- Values 1.0-1.1: Mild repetition control (good for most tasks)
- Values 1.1-1.3: Stronger anti-repetition (helpful for verbose outputs)
- Values >1.5: May produce unnatural phrasing
The parameter operates by modifying the token probability distribution during generation - tokens that have appeared in the recent context have their probabilities reduced by the penalty factor. This happens dynamically throughout generation, making it more effective than simple post-processing filters. Like other generation parameters, repeat penalty follows the skill > model > global hierarchy, allowing you to configure strict anti-repetition for technical writing while allowing more repetition in poetic outputs.
2.3.4. Top-k
Top-k is a generation parameter that restricts token selection to the K most probable tokens at each step, regardless of their actual probability values. For example, with top_k=40, the model only considers the 40 highest-probability tokens when generating each new token.
Usage considerations:
- Lower values (20-40): More focused, conservative outputs
- Higher values (50-100): Greater diversity within coherence
- Value of 0: Disables top-k filtering (uses full vocabulary)
Unlike temperature which affects probability distribution shape, top-k creates a hard cutoff - tokens outside the top K have zero chance of selection. This provides more deterministic control over output diversity. The parameter follows the standard skill > model > global hierarchy, allowing context-specific tuning. While less commonly adjusted than temperature or top-p, top-k offers valuable fine control for specialized tasks where you want to strictly limit the token selection pool.
2.3.5. Min-p
Min-p (minimum probability threshold) is an advanced generation parameter that filters tokens whose probability falls below a specified fraction of the highest-probability token's probability. For example, with min_p=0.05, only tokens with probability ≥5% of the top token's probability are considered.
Key characteristics:
- Range 0.0-1.0 (0.0 disables the filter)
- Complements rather than replaces top-p
- More adaptive than fixed top-k
This parameter helps eliminate extremely low-probability "tail" tokens that might produce nonsensical outputs, while maintaining more flexibility than strict top-k filtering. It's particularly useful for:
- Reducing rare factual errors
- Preventing improbable word combinations
- Maintaining response coherence in long outputs
Like other generation parameters, min_p follows the skill > model > global hierarchy, though it's typically left at default (0.0) unless addressing specific output quality issues. Advanced users might experiment with min_p=0.03-0.07 for critical applications requiring maximum response reliability.
2.3.6. Thread Count
Thread count specifies the number of CPU threads dedicated to the
core AI inference process (configured via thread_count in
YAML). This parameter primarily affects how efficiently the system
utilizes your CPU's computational resources during token
generation. Token generation is typically bound by RAM speed and not
by CPU compute.
The parameter targets the phase or transforming tokens through the neural network layers. Since this phase is often limited by memory bandwidth rather than pure compute, increasing threads beyond your RAM's capability won't improve speed but will keep your CPU cores uselessly busy-waiting for data.
For instance on AMD Ryzen 5 5600G I observed that AI throughput gains start diminishing fast after about 3 threads have been utilized. And there is almost no performance difference between 5 and 6 threads despite CPU claiming to have 12 threads. Reason is that RAM bandwidth gets fully utilized already very fast with just few threads.
2.3.7. Batch Thread Count
Batch thread count specifies threads used for prompt preprocessing
(configured via batch_thread_count). This parameter affects how
quickly the system parses your input text for the AI model.
Unlike thread_count which handles token generation, this phase is typically compute-bound rather than RAM-bound, so higher values often help up to your CPU's logical core count.
2.3.8. Context Size Tokens
Context size tokens defines the maximum number of tokens
(word-pieces) a model can process, configured per-model via
context_size_tokens. This parameter represents the AI's "working
memory" capacity for any given task.
Critical implications:
- Determines maximum input+output length.
- Larger contexts require significantly more RAM.
- Most models support 4K-128K tokens.
This parameter fundamentally shapes what tasks a model can handle - code analysis of large files, book chapter processing, or multi-document summarization all require sufficient context size. Always verify your model's actual supported context - exceeding it causes unpredictable or significantly degraded model output.
2.3.9. Timeout
Timeout is a parameter that specifies the maximum time (in milliseconds) that the AI is allowed to run for a task. If this time is exceeded, the process is terminated, and the response is marked with "TERMINATED BY TIMEOUT".
The timeout parameter can be set at three levels:
- Skill-specific: Defined in the skill YAML file.
- Model-specific: Defined in the model configuration.
- Global default: Set in the main configuration file.
The priority hierarchy is: skill > model > global default.
For example, to set a 5-minute timeout (300,000 milliseconds) for a specific skill, add:
timeout_millis: 300000
in the skill's YAML file.
In the model configuration:
models: - alias: "mistral" timeout_millis: 600000 # ... other parameters
In the main configuration:
default_timeout_millis: 120000
Setting a timeout of 0 means no timeout.
This feature helps prevent stuck AI processes and ensures predictable task completion times.
2.3.10. Parameter Precedence Hierarchy
Älyverkko CLI implements a sophisticated three-tier parameter precedence hierarchy for generation settings (temperature, top_p, etc.):
- Skill-specific values (highest priority)
- Defined in skill YAML files
- Example:
temperature: 0.3insummary.yaml
- Model-specific values (middle priority)
- Defined in model configuration
- Example:
temperature: 0.6for "mistral" model
- Global defaults (lowest priority)
- Set in main configuration
- Example:
default_temperature: 0.7
The system automatically selects the most specific applicable value, creating a flexible "rule cascade" where specialized configurations override broader ones.
2.4. AI response post processing parameters
2.4.1. Final answer indicator
The final_answer_indicator is a optional, model-specific configuration parameter that enables automatic separation of an AI's response into two distinct sections:
- INTERNAL THOUGHTS
- The AI's reasoning process, step-by-step analysis, and intermediate calculations
- ASSISTANT
- The concise final answer or conclusion
This way, user can easily skip to final answer without reading through lengthy reasoning. It is good for scenario where the reasoning process is detailed but the conclusion is what matters most.
This is only useful for thinking LLMs that produce internal thought monologue before producing final response. Parameter is model specific because different thinking models can use different ways to signal end of internal thought and transition to final response mode.
How It Works:
You define a unique string marker (e.g.,
"<final_answer>") in your model's configuration:models: - alias: "mistral" filesystem_path: "Mistral-Large-Instruct-2407.Q8_0.gguf" context_size_tokens: 32768 final_answer_indicator: "<final_answer>"
- When the AI generates a response:
- The system searches for the exact marker string in the response
- If found, it splits the response into two parts:
- Everything before the marker →
INTERNAL THOUGHTS - Everything after the marker →
ASSISTANT
- Everything before the marker →
- If the marker is not found, the entire response appears in
ASSISTANT(fallback behavior)
Output Formatting: The processed response is saved in your task file with this structure:
DONE: skill=default model=mistral duration=38m * USER: [Original question] * INTERNAL THOUGHTS: [AI's reasoning process] * ASSISTANT: [Final answer]
2.4.2. End of text marker
An end of text marker is an optional string (e.g., "###", ”[end of text]“) specified per-model that signals the AI has completed its response. When configured, Älyverkko CLI automatically truncates output at this marker, removing any trailing artifacts.
This parameter is useful with models that use specific termination sequences so that they will not be shown to the AI user.
For example, if a model typically ends responses with "###", setting
end_of_text_marker: "###" ensures the system removes "###" at the
end of AI response.
3. Installation
When you first encounter Älyverkko CLI, the setup process might seem involved compared to cloud-based AI services. That's completely understandable! Let me walk you through why each step exists and how it ultimately creates a powerful, private, and cost-effective AI assistant that works for you.
3.1. Requirements
Operating System:
Älyverkko CLI is developed and tested on Debian 13 "Bookworm". It should work on any modern Linux distribution with minimal adjustments to the installation process.
Dependencies:
- Java Development Kit (JDK) 17 or higher
- Apache Maven for building the project
Hardware Requirements:
- Modern multi-core CPU.
- The more RAM you have, the smarter AI model you can use. For example, at least 64 GB of RAM is needed to run decent AI models with sufficiently large context.
- Sufficient disk space to store large language models and input/output data.
3.2. Your Setup Journey - What to Expect
Before we start actual setup, here's brief overview of what you'll be doing:
Installing Java & Maven (The Foundation)
- What: Install JDK 21+ and Apache Maven
- Why: Älyverkko CLI is written in Java - these tools let you build and run the application. Key insight: Java was chosen because it's cross-platform, memory-safe, and perfect for long-running background processes like our AI task processor.
Building llama.cpp (Your AI Engine):
- What: Download and compile the llama.cpp project from GitHub.
- Why: This is the actual "brain" that runs large language models on your CPU. We build from source (rather than using rebuilt binaries) so it can optimize for your specific CPU - squeezing out maximum performance from your hardware.
Adding AI Models (The Brains):
- What: Download GGUF format model files (typically 4-30GB each)
- Where: From Hugging Face Hub (search "GGUF").
- Why: These contain the actual neural networks that power the AI.
Running the Interactive Wizard setup wizard:
- What: Launch the configuration wizard that asks simple questions.
You'll answer questions like "Where did you put your AI models?"
with easy prompts. Key insight: This creates your personal
~/.config/alyverkko-cli.yamlfile. Note: The wizard automatically detects your models and suggests reasonable defaults - you're not starting from scratch.
Setting Up "Skills" (Your Custom Instructions)
- What: You will create simple YAML files defining how the AI should behave for different tasks.
- Why: So you don't have to rewrite instructions every time ("be a coding assistant" vs "be a writing editor"). Don't worry: You can start with sample skills and you can modify them gradually.
Preparing Your First Task (The Magic Moment)
- What: Create task text file with your request, prefixed with TOCOMPUTE:
- Why: This triggers the background processing system and verifies that everything is working correctly.
3.3. Installation
At the moment, to use Älyverkko CLI, you need to:
- Download sources and build llama.cpp project.
- Download sources and build Älyverkko CLI project.
- Download one or more pre-trained large language models in GGUF format. Hugging Face repository has lot of them.
Follow instructions for obtaining and building Älyverkko CLI on your computer that runs Debian 13 operating system:
Ensure that you have Java Development Kit (JDK) installed on your system.
sudo apt-get install openjdk-21-jdk
Ensure that you have Apache Maven installed:
sudo apt-get install maven
- Clone the code repository or download the source code for the `alyverkko-cli` application to your local machine.
- Navigate to the root directory of the cloned/downloaded project in your terminal.
Execute the installation script by running
./install
This script will compile the application and install it to directory
/opt/alyverkko-cli
To facilitate usage from command-line, it will also define system-wide command alyverkko-cli as well as "Älyverkko CLI" launcher in desktop applications menu.
- Prepare Älyverkko CLI configuration file.
- Verify that the application has been installed correctly by running alyverkko-cli in your terminal.
3.4. Alyverkko CLI daemon configuration
Älyverkko CLI application configuration is done by editing YAML formatted configuration file.
Configuration file should be placed under current user home directory:
~/.config/alyverkko-cli.yaml
3.4.1. Key Parameters Explained
3.4.1.1. Core Directories
tasks_directory: Where task files are placed for processing.models_directory: Contains GGUF model files.skills_directory: Contains YAML skill definition files.llama_cli_path: Path to llama.cpp's llama-completion executable.
3.4.1.2. Generation Parameters
default_temperature: (Optional) Creativity control (0-3, higher = more creative).default_top_p: (Optional) Nucleus sampling threshold (0.0-1., higher = more diverse).default_top_k: (Optional) Restricts token selection to the K tokens with the highest probabilities, regardless of their actual probability values or the shape of the distribution.default_min_p: (Optional) Filters the vocabulary to include only tokens whose probability is at least a certain fraction (Min P) of the probability of the most likely token.default_repeat_penalty: (Optional) Penalty for repetition (>0.0, 1.0 = no penalty)
3.4.1.3. Performance Tuning
thread_count: Sets the number of threads to be used by the AI during response generation. RAM data transfer speed is usually bottleneck here. When RAM bandwidth is saturated, increasing thread count will no longer increase processing speed, but it will still keep CPU cores unnecessarily busy.batch_thread_count: Specifies the number of threads to use for input prompt processing. CPU computing power is usually the bottleneck here.
3.4.1.4. Model-Specific Settings
Each model in the models list can have:
alias: Short model alias. Model with alias "default" would be used by default.temperature: (Optional) See: Temperaturetop_p: (Optional) See: Top-p (Nucleus Sampling)min_p: (Optional) See: Min-ptop_k: (Optional) See: Top-krepeat_penalty: (Optional) See: Repeat Penaltyfilesystem_path: File name of the model as located within models_directorycontext_size_tokens: Context size in tokens that model was trained on.end_of_text_marker: (Optional) Some models produce certain markers to indicate end of their output. If specified here, Älyverkko CLI can identify and remove them so that they don't leak into conversation. Default value is: null.final_answer_indicator: (Optional) Marker that allows to separate thinking LLM internal thought from final response. Read more: Final answer indicator.
3.4.2. Configuration file example
The application is configured using a YAML-formatted configuration file. Below is an example of how the configuration file might look:
tasks_directory: "/home/john/AI/tasks" models_directory: "/home/john/AI/models" skills_directory: "/home/john/AI/skills" llama_cli_path: "/home/john/AI/llama.cpp/build/bin/llama-completion" # Generation parameters default_temperature: 0.7 default_top_p: 0.9 default_repeat_penalty: 1.0 # Performance tuning thread_count: 6 batch_thread_count: 10 # Model definitions models: - alias: "default" filesystem_path: "model.gguf" context_size_tokens: 64000 temperature: 0.6 top_p: 0.95 top_k: 20 min_p: 0 repeat_penalty: 1.1 - alias: "mistral" filesystem_path: "Mistral-Large-Instruct-2407.Q8_0.gguf" context_size_tokens: 32768
3.4.3. Enlisting available models
Once Älyverkko CLI is installed and properly configured, you can run following command at commandline to see what models are available to it:
alyverkko-cli listmodels
Note: Models that reference missing files will be automatically marked with "-missing" suffix in their alias by configuration wizard. You can manually remove this suffix after fixing the model file path.
3.4.4. Self test
The selftest command performs a series of checks to ensure the system is configured correctly:
alyverkko-cli selftest
It verifies:
- Configuration file integrity.
- Model directory existence.
- The presence of the llama.cpp executable.
3.5. Skill concept and configuration
- See also: Skill concept explanation.
3.5.1. Skill File Format
Skills are defined in YAML files stored in the skills_directory.
Each skill file contains:
prompt: "Full system prompt text here" model_alias: mistral # Optional temperature: 0.8 # Optional top_p: 0.95 # Optional top_k: 20 # Optional min_p: 0 # Optional repeat_penalty: 1.1 # Optional
The system prompt must contain <TASK-FILE> which gets replaced with the actual user prompt during execution.
3.5.2. Example Skill File
writer.yaml
temperature: 0.9 top_p: 0.95 model_alias: mistral prompt: | <|im_start|>system User will provide you with task that needs to be solved along with existing relevant information. You are artificial general intelligence system that always provides well reasoned responses. <|im_end|> <|im_start|>user /think Solve following problem: <TASK-FILE> <|im_end|> <|im_start|>assistant
See more example skills: default.yaml, summary.yaml
3.6. Starting process daemon
Älyverkko CLI keeps continuously listening for and processing tasks from a specified mail directory.
There are multiple alternative ways to start Älyverkko CLI in mail processing mode:
3.6.0.1. Start via command line interface
- Open your terminal.
Run the command:
alyverkko-cli process
- The application will start monitoring the configured mail directory for incoming messages and process them accordingly in endless loop.
- To terminate Älyverkko CLI, just hit CTRL+c on the keyboard, or close terminal window.
3.6.0.2. Start using your desktop environment application launcher
- Access the application launcher or application menu on your desktop environment.
- Search for "Älyverkko CLI".
- Click on the icon to start the application. It will open its own terminal.
- If you want to stop Älyverkko CLI, just close terminal window.
3.6.0.3. Start in the background as systemd system service
During Älyverkko CLI installation, installation script will prompt you if you want to install systemd service. If you chose Y, Alyverkko CLI would be immediately started in the background as a system service. Also it will be automatically started on every system reboot.
To view service status, use:
systemctl -l status alyverkko-cli
If you want to stop or disable service, you can do so using systemd facilities:
sudo systemctl stop alyverkko-cli sudo systemctl disable alyverkko-cli
3.7. The Light at the End of the Tunnel
After setup, here's what you get:
- ✅ A silent background process that automatically processes tasks
- ✅ Complete privacy - no data ever leaves your machine (if you don't synchronize tasks directory)
- ✅ The ability to run state-of-the-art models without overly expensive hardware.
- ✅ A system that keeps working while you sleep - queue up 10 tasks before bed, get results in the morning.
You fill find that after the first few processed tasks, the initial setup effort feels worthwhile. You're not just getting another chat bot - you're building a personal AI workstation tailored to your specific needs. The initial investment pays dividends every time you need serious AI power without compromise.
4. Usage
4.1. Task file format
Task files follow a specific structure that begins with a header line:
TOCOMPUTE: [parameters] [User prompt content]
TOCOMPUTE: skill=default model=default priority=5 If numbers had personalities, what kind of personality might the number 'zero' have?
4.1.1. Task File Header Format
The first line must begin with exactly TOCOMPUTE: followed by
space-separated key-value pairs:
TOCOMPUTE: skill=default model=mistral priority=10
Valid parameters in the header:
skill[name]=: Specifies which skill to use (defaults to "default")model[alias]=: Specifies which AI model to use (defaults to "default")priority[integer]=: Higher integers mean higher priority (default: 0)
4.1.2. Processed File Format
After AI processing completes, a new file is created with:
- First line:
DONE: skill[name] model=[alias] duration=[time]= * USER:section containing original user prompt* ASSISTANT:section containing AI response
DONE: skill=writer model=default duration=5m ...
DONE: skill=default model=default duration=2m
* USER:
If numbers had personalities,
what kind of personality might the number 'zero' have?
* ASSISTANT:
1. Personality traits based on mathematical properties:
- Neutral and unchanging unless influenced
- Control over magnitude through multiplication
- Neither positive/negative (impartial)
- Foundational yet seemingly insignificant at times
2. Symbolism and metaphors:
- Balance point between opposites
- Container for infinite possibilities (potential)
- Cycle of beginning/endpoints
- Quiet supporter behind the scenes
3. Social dynamics:
- Values community/cooperation
- May feel undervalued but persists regardless
- Adaptable depending on situation/placement
4. Philosophical/spiritual parallels:
- Emptiness equates to purity/clean slate
- Potential without action = dormant power
5. Gender and self-identity:
- Ambiguous/genderless
6. Emotional characteristics:
- Patient; allows time for events/actions to unfold
- Resilient when facing neglect or misunderstanding
- Persistent in fulfilling its purpose
7. Behavioral tendencies:
- Fosters growth indirectly rather than directly contributing
measurable output
- Encourages exploration beyond limits via abstract reasoning
innovations
4.2. Task preparation
The Älyverkko CLI application expects input files for processing in the form of plain text files within the specified tasks directory (configured in the YAML configuration file).
Suggested usage flow is to prepare AI assignments within the Älyverkko CLI mail directory using normal text editor. Once AI assignment is ready for processing, you should initiate AI processing on that file.
4.2.1. "joinfiles" command
Note: See also alternative solution with similar goal: prelude.
The joinfiles command is a utility for aggregating the contents of multiple files into a single document, which can then be processed by AI. This is particularly useful for preparing comprehensive problem statements from various source files, such as software project directories or collections of text documents.
4.2.1.1. Usage
To use the joinfiles command, specify the source directory containing the files you wish to join and a topic name that will be used to generate the output file name:
alyverkko-cli joinfiles -s /path/to/source/directory -t "my_topic"
If desired, you can also specify a glob pattern to match only certain files within the directory:
alyverkko-cli joinfiles -s /path/to/source/directory -p "*.java" -t "my_topic"
After joining the files, you can choose to open the resulting document in text editor for further editing or review:
alyverkko-cli joinfiles -t "my_topic" --edit
4.2.1.2. Options
- -s, –src-dir: Specifies the source directory from which to join files.
- -p, –pattern: An optional glob pattern to match specific files within the source directory.
- -t, –topic: The topic name that will be used as a basis for the output file name and should reflect the subject matter of the joined content.
- -e, –edit: Opens the joined file in text editor after the join operation is complete.
4.2.1.3. Example Use Case
Imagine you have a software project with various source files that you want to analyze using AI. You can use the joinfiles command to create a single document for processing:
alyverkko-cli joinfiles -s /path/to/project -p "*.java" -t "software_analysis" --edit
This will recursively search the project directory for Java source files, aggregate their contents into a file named software_analysis.org (within AI processor input files directory), and open text editor on the file, so that you can add your analysis instructions or problem statement. Finally you Initiate AI processing and after some time, you will get results and the end of the file.
4.3. Initiate AI processing
Once your task file is prepared, you should place TOCOMPUTE: marker on the first line of that file, so that it will be considered for processing.
When the Älyverkko CLI detects a new or modified file in the mail directory:
- It checks if file has "TOCOMPUTE:" on the first line. If no, file is ignored. Otherwise Älyverkko CLI continues processing the file.
- It reads the content of the file and feeds it as an input for an AI model to generate a response.
- Once the AI has generated a response, the application appends this response to the original mail contents within the same file, using org-mode syntax to distinguish between the user's query and the assistant's reply. The updated file will contain both the original query (prefixed with: "* USER:*") and the AI's response (prefixed with "* ASSISTANT:"), ensuring a clear and organized conversation thread. "TOCOMPUTE:" is removed from the beginning of the file to avoid processing same file again.
Note: During AI task file preparation, feel free to save intermediary states as often as needed because AI engine will keep ignoring the file until TOCOMPUTE: line appears. Once AI assignment is ready, add
TOCOMPUTE:
to the beginning of the file and save one last time. Älyverkko CLI will detect new task approximately within one second after file is saved and will start processing it.
If your text editor automatically reloads file when it was changed by other process in the filesystem, AI response will appear within text editor as soon as AI response is ready. If needed, you can add further queries at the end of the file and re-add "TOCOMPUTE:" at the beginning of the file. This way AI will process file again and file becomes stateful conversation. If you use GNU Emacs text editor, you can benefit from purpose-built GNU Emacs utilities.
4.4. Helpful GNU Emacs utilities
Note: GNU Emacs and following Emacs Lisp utilities are not required to use Älyverkko CLI. Their purpose is to increase comfort for existing GNU Emacs users.
4.4.1. Easily compose new problem statement for AI from emacs
The Elisp function ai-new-topic facilitates the creation and opening of a new Org-mode file dedicated to a user-defined topic within a specified directory. Now you can use this file within emacs to compose you problem statement to AI.
When ai-new-topic function triggered, it first prompts the user to input a topic name. This name will serve as the basis for the filename and the title within the document.
The function then constructs a file path by concatenating the
pre-defined alyverkko-topic-files-directory (which should be set to
your topics directory), the topic name, and the .org extension. If a
file with this path does not already exist, the function will create a
new file and open it for editing.
(defvar alyverkko-task-files-directory "/home/user/my-ai-tasks-directory/" "Directory where task files are stored.") (defun alyverkko-new-task () "Create and open a task file in the specified directory." (interactive) (let ((task (read-string "Enter task name: "))) (let ((file-path (concat alyverkko-task-files-directory task ".org"))) (if (not (file-exists-p file-path)) (with-temp-file file-path )) (find-file file-path) (goto-char (point-max)) (org-mode))))
4.4.2. Easily signal to AI that problem statement is ready for solving
The function alyverkko-compute is designed to enhance the workflow
of users working with the Älyverkko CLI application by automating the
process of marking text files for computation with a specific AI model
and prompt.
When function is invoked, it detects available prompts and allows user to select one.
Thereafter function detects available models from Älyverkko CLI configuration file and allows user to select one.
Finally function inserts at the beginning of currently opened file something like this:
TOCOMPUTE: prompt=<chosen-prompt> model=<chosen-model> priority=<chosen-priority>
- Adjust prompt-dir variable to point to your prompts directory.
- Adjust config-file variable to point to your Älyverkko CLI configuration file path.
(defun alyverkko-compute () "Interactively pick a skill, model, and priority, then insert a TOCOMPUTE line at the top of the current buffer. Adjust `skill-dir` and `config-file` to match your setup." (interactive) (let ((skill-dir "~/.config/alyverkko-cli/skills/") (config-file "~/.config/alyverkko-cli/alyverkko-cli.yaml") models) ;; Harvest model aliases from the Älyverkko CLI config (with-temp-buffer (insert-file-contents config-file) (goto-char (point-min)) (when (search-forward-regexp "^models:" nil t) (while (search-forward-regexp "^\\s-+- alias: \"\\([^\"]+\\)\"" nil t) (push (match-string 1) models)))) (if (file-exists-p skill-dir) (let* ((files (directory-files skill-dir t "\\`[^.].*\\.yaml\\'")) (aliases (mapcar #'file-name-base files))) (if aliases (let* ((selected-alias (completing-read "Select skill: " aliases)) (model (completing-read "Select AI model: " models)) (priority (number-to-string (read-number "Priority (integer, default 0): " 0)))) (alyverkko-insert-tocompute-line selected-alias model priority)) (message "No skill files found."))) (message "Skill directory not found.")))) (defun alyverkko-insert-tocompute-line (skill-alias model &optional priority) "Insert a TOCOMPUTE line with SKILL-ALIAS, MODEL, and PRIORITY at the top of the current buffer." (save-excursion (goto-char (point-min)) (insert (format "TOCOMPUTE: skill=%s model=%s priority=%s\n" skill-alias model (or priority "0"))) (save-buffer)))
5. Getting the source code
- This program is free software: released under Creative Commons Zero (CC0) license.
- Program author:
- Svjatoslav Agejenko
- Homepage: https://svjatoslav.eu
- Email: mailto://svjatoslav@svjatoslav.eu
- Other software projects hosted at svjatoslav.eu
5.1. Source code
- Download latest snapshot in TAR GZ format
- Browse Git repository online
Clone Git repository using command:
git clone https://www3.svjatoslav.eu/git/alyverkko-cli.git
- See JavaDoc.
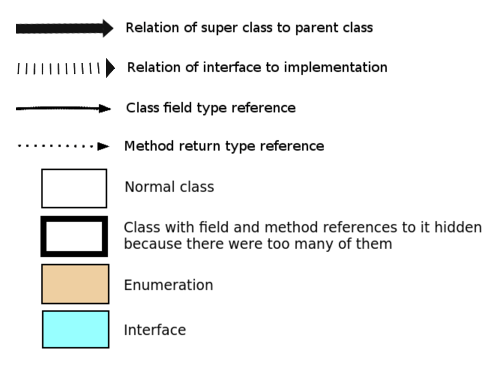
- See automatically generated class diagrams. Here is legend to help understand diagrams. Diagrams were generated using JavaInspect tool.
{kind=link}
6. Feature ideas
- Recommend some concrete AI models.
- In task directory ignore binary files, use joinfiles command as example how to ignore binary files. Perhaps extract plain text file detection into some utility class.
- Make text editor configurable in application properties file.
- Extend the application's capabilities to include voice capture and processing.
- Implement image capture and processing features.